- Research article
- Open access
- Published:
Analysis of disruptive selection in subdivided populations
BMC Evolutionary Biology volume 3, Article number: 22 (2003)
Abstract
Background
Analytical methods have been proposed to determine whether there are evolutionarily stable strategies (ESS) for a trait of ecological significance, or whether there is disruptive selection in a population approaching a candidate ESS. These criteria do not take into account all consequences of small patch size in populations with limited dispersal.
Results
We derive local stability conditions which account for the consequences of small and constant patch size. All results are derived from considering Rm, the overall production of successful emigrants from a patch initially colonized by a single mutant immigrant. Further, the results are interpreted in term of concepts of inclusive fitness theory. The condition for convergence to an evolutionarily stable strategy is proportional to some previous expressions for inclusive fitness. The condition for evolutionary stability stricto sensu takes into account effects of selection on relatedness, which cannot be neglected. It is function of the relatedness between pairs of genes in a neutral model and also of a three-genes relationship. Based on these results, I analyze basic models of dispersal and of competition for resources. In the latter scenario there are cases of global instability despite local stability. The results are developed for haploid island models with constant patch size, but the techniques demonstrated here would apply to more general scenarios with an island mode of dispersal.
Conclusions
The results allow to identity and to analyze the relative importance of the different selective pressures involved. They bridge the gap between the modelling frameworks that have led to the Rm concept and to inclusive fitness.
Background
Various criteria have been proposed to compute the stable states of the evolutionary dynamics of traits of ecological significance. Previous works ("adaptive dynamics", e.g., [1–6]) have highlighted the need to distinguish different kinds of stability. A strategy is convergence stable if the population evolves towards it by allelic substitutions. A convergence stable strategy is evolutionarily stable (non-invasible) if rare deviants are selected against. Otherwise, there is disruptive selection, and "branching" of the distribution of phenotypes in the population may occur [3, 6].
When fitness can be evaluated exactly, the different kinds of stability can be evaluated. However, in many cases approximations are useful, either because exact results are not available or because they are too complex to allow better understanding of evolution. This occurs when populations are structured in patches occupied by a small number of individuals. In such a case, a widely used measure of fitness effects is inclusive fitness. Inclusive fitness measures fitness effects as the effect of a deviant strategy on the fitness of an individual which expresses this strategy, plus the effect on the fitness of an individual when the strategy is expressed by other individuals in the patch, the latter effect being weighted by a measure of genetic similarity of individuals within a patch [7]. Although the inclusive fitness approach often allows to identify selective pressures, it is desirable to integrate it in a more general framework where the different kinds of dynamics are distinguished [8]. Can inclusive fitness be used to compute convergence stability, evolutionary stability, or both? Some works made no distinction between the concepts of convergence and of evolutionary stability [9], while others have found that inclusive fitness is suitable for evaluating convergence stability but not for evolutionary stability [10, 11]. There have been some attempts to derive evolutionary stability conditions using inclusive fitness concepts (see [10] and references therein) but further insight into the above issues has been limited by a dearth of well-established results which could be compared to some alternative approach.
This paper will provide such results, using the Rm concept introduced in ref. [12]. Rm is the overall production of successful emigrants from a patch, descended from a single mutant immigrant. Ref. [12] presents an exact numerical method to compute Rm in complex metapopulation models (also used in ref. [13]), but analytical conditions for convergence and evolutionary stability can also be deduced from Rm. In this paper I show how this can be done. In particular, a new result is the analytical condition for local invasibility versus non-invasibility (i.e. evolutionary stability) of a convergence stable strategy for the island model of dispersal. Kin selection effects are taken into account in this computation, as the kin interactions that occur in the patch all the way from colonization to local allele extinction. Thus, we should also be able to recover known inclusive fitness expressions from Rm, but how we can do that is not a priori obvious. We will see that inclusive fitness can be derived as a measure of local convergence stability from Rm. But the evolutionary stability condition can also be understood in terms of the concepts of inclusive fitness theory.
Rather than considering the complex metapopulation model of ref. [12], I will consider discrete-time models which assume a constant number N of haploid adults per patch. This should help to see the logic of the method. Within this setting, I will analyze some basic models widely considered in previous works, dealing with the evolution of dispersal and with disruptive selection under competition for resources.
Results
We consider here models where N adults reproduce within each of a large ("infinite") number of patches. A large number of juveniles are produced by each adult. A fraction of them disperse, in which case they disperse randomly over all patches, following an "island" or "global" mode of dispersal. The juveniles then compete for access to reproduction so that exactly N of them survive this competition in each patch. No other exact assumption about reproduction, competition and dispersal is done at this stage (this is done later in applications).
The number of successful emigrants Rm
We consider Rm, the overall production of successful emigrants from a patch, descended from a single mutant immigrant in this patch. By successful I mean that the individual settles as one of the N adults in a patch. As originally described [12], Rm counts individuals before the dispersal cost is paid and competition occurs, so that it counts the number of emigrant descendants, successful or not, of each emigrant, successful or not. Both definitions are effectively equivalent.
The mutant is considered rare enough at the metapopulation level that no further mutant immigrant occurs in the patch and no mutant will be encountered by emigrants. Rm is a generalization of the net reproductive rate R0 (or lifetime reproductive success) often considered in demography (e.g., [14, 15]). However, Rm does not count the number of offspring one generation later, but the number of successful emigrants from a patch, descended over several generations from one successful immigrant in this patch. Rm is an appropriate fitness measure because all successful emigrants are equivalent in terms of their fitness expectations. The number of successful emigrants is counted until local extinction of the family descended from the immigrant. Even without local patch extinction, local extinction of the family occurs due to the recurrent inflow of other immigrants.
Exact computation of Rm
For this computation, we follow the distribution of the number of descendants of the immigrant mutant over successive generations. N offspring are sampled independently from a large number of juveniles. Let π j be the probability that a randomly chosen offspring comes from one of the j mutants in the patch in the previous generation. π j is a function of the mutant and resident strategies (for examples, see the Applications below). Then, the probabilities a kj that there are k mutant descendants from j mutant parents in the patch are binomial terms:

where

is the binomial coefficient, N!/[k!(N - k)!]. These transition probabilities define a Markov chain with one absorbing state (local extinction of the mutant allele). Now let A = (a kj ) for k = 1, ..., N, j = 1, ..., N (i.e., mutant allele being present). For j > 0, the probability of having j mutants in the patch in generation t is given by p j ≡ (Ati) j , where i is a vector representing the initial distribution of the mutant: a single mutant is represented as i ≡ (1,0,...,0)T, where T denotes transpose. In each generation, the expected number of successful emigrant gametes of each mutant adult in a patch with j mutants is written g j . The number of successful emigrant mutant gametes produced by the patch in generation t is therefore h j ≡ jg j . Let h ≡ (h j ). The expected outflow of successful mutants from the patch can be written

Therefore, summing over generations we obtain the fitness measure R m in the form

where B ≡ (I - A)-1. This is a simple discrete time version of eq. 6 in ref. [12].
Rm is a function of the resident strategy z and of the mutant strategy, whose deviation from z is denoted δ. Local stability conditions are given in terms of the first- and second-order derivatives of the fitness measure [4–6]. We use the prime notation for differentiation with respect to δ throughout the paper. A strategy z* is a candidate ESS (evolutionarily stable strategy) if 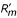 = 0 at z*. A candidate ESS z* is locally convergence stable if > 0 at z <z* and < 0 at z >z*, so that selection brings a population expressing strategy z ≠ z* closer to z*. Hence, a strategy is locally convergence stable if d/dz < 0 at z*, where is evaluated at δ = 0 before the derivation with respect to z is carried out. It is locally non-invasible if
= 0 at z*. A candidate ESS z* is locally convergence stable if > 0 at z <z* and < 0 at z >z*, so that selection brings a population expressing strategy z ≠ z* closer to z*. Hence, a strategy is locally convergence stable if d/dz < 0 at z*, where is evaluated at δ = 0 before the derivation with respect to z is carried out. It is locally non-invasible if 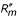 < 0 at z* (for the borderline case = 0, see [16]). In the following sections, we provide analytical expressions for and .
< 0 at z* (for the borderline case = 0, see [16]). In the following sections, we provide analytical expressions for and .
A technical device underlying results below is the expansion of derivatives of h j and π j in terms of powers of j. Results will rely upon the highest order term in these expansions being j2 for the first-order derivatives with respect to δ, and j3 for the second-order derivatives. This holds because, whether interactions between individuals are additive or not, h j and π j can be expanded in terms of δ times the sum (or average) of individual phenotypes in the patch, plus δ2 times the sum of products of pairs of individual phenotypes, plus δ2 times the sum of products of three phenotypes, and so on. Dominance of allelic effects in diploid populations raises an exception to this pattern (see Discussion).
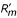 and relatedness
and relatedness
Let w j (δ) be the expected number of adult offspring (emigrant or not) of a mutant parent among j mutant parents. The expected number of offspring jw j of the j mutants in the next generation is simply the sum of the expected number of successful emigrants (h j ) and of locally settled offspring (N π j ). That is,
h j (δ) + N π j (δ) = jw j (δ). (4)
In the Appendix, it is shown that
can be written as

where d is the probability that an adult is an immigrant in a population following the resident strategy,  and
and  are the coefficients of j and j2/N in the expansion for
are the coefficients of j and j2/N in the expansion for  , and F is the probability that two individuals sampled with replacement in a patch have a common ancestor in the patch.
, and F is the probability that two individuals sampled with replacement in a patch have a common ancestor in the patch.
Simple and well-known arguments are available to compute F [17, 18], so it is useful to express in terms of F. Between two successive generations t and t + 1, F obeys the recursion
F (t + 1) = 1/N + (1 - 1/N)(1 - d)2 F(t) (6)
where 1/N is the probability that the same individual is sampled twice, (1 - d)2 is the probability that two different individuals are both non-immigrants, and then F(t) is the probability that their parent(s) was or were from the same family, i.e. descend from the same immigrant. Thus the stationary value of F is

The definition of F as the probability that two individuals descend from the same immigrant is also a definition of the genetic structure parameters used in population genetics (e.g., [17]), which are often used as relatedness coefficients in kin selection theory (e.g., [19, 20]). Hence F is a relatedness coefficient. Indeed we can write
= WIF/d (8)
where WIF is the inclusive fitness considered in other works (see the dispersal example for a concrete illustration). The 1/d factor means that Rm measures effects of selection over an average of 1/d generations, in contrast to WIF which measures them over one generation.
is a function of the resident strategy z. As noted above, serves to find candidate ESSs z* such that = 0 at z*. Local convergence stability is determined by the sign of around z*, which may be deduced from the sign of d/dz at z*. As the Applications below show, it may not be necessary to compute d/dz to obtain the sign of and thus to check convergence stability.
We now consider invasion by mutants near a candidate ESS z*. To express we generalize the κ notation introduced above. Let  (f),
(f),  (f) and
(f) and  (f) be the coefficients of j, j2/N and j3/N2 in the expansion for some quantity f. We obtain
(f) be the coefficients of j, j2/N and j3/N2 in the expansion for some quantity f. We obtain

where K is the probability that three individuals sampled with replacement in the same patch descend from the same immigrant. K can be computed by the same methods as F, as detailed in the Appendix. All elements here are evaluated at δ = 0. A proof is presented in the Appendix, and evaluation of this formula in the Applications was checked against numerical evaluation of Rm by eq. 3. The second line of eq. 9 includes fitness effects depending on changes in relatedness due to selection (see Discussion). In general, π
j
is of the order of 1/N, F is of the order of 1/N and K of the order of 1/N2, so the whole second line of eq. 9 is of the order of 1/N and cannot be easily neglected relative to the remainder of .
Applications
Here we apply the above results first to a simple model of evolution of dispersal [21]. Although disruptive selection has been found in other dispersal models (e.g., [22–24]), it is not expected to occur in this model, which serves mainly to compare the present approach with a previous computation of stable strategies. Next we consider two models of resource competition, one of which was previously considered in ref. [25]. These are small patch, limited dispersal versions of a class of models of competition widely considered in previous works: see e.g. [16, 25–29], and references therein.
Dispersal
The trait under selection is the dispersal probability of juveniles, and there is a survival cost c of dispersal: the survival probability of dispersed juveniles is (1 - c) times that of philopatric ones. For mutants with dispersal z + δ, the probability that an individual is the philopatric descendant of a mutant parent is

This expression is obtained as the ratio of the relative number of mutant juveniles that do not disperse [which is 1 - (z + δ) for each of j mutant parents] to the relative number of juveniles which come in competition in the patch. The latter is the number of philopatric juveniles, 1 - (z + δ) for each of the j mutant parents and 1 - z for each of the N - j non-mutants, plus the relative number of immigrant juveniles from other patch, which is Nz(1 - c) as parents in other patches are not mutants and their juveniles pay the cost of dispersal.
Likewise, the number of successful emigrant offspring of each deviant parent is

because each deviant parent contributes a relative number (1 - c)(z + δ) of emigrant juveniles which compete with a relative number N [1 - z + (1 - c)z] = N(1 - zc) of competing juveniles in every other patch, and N adult offspring are sampled out of these juveniles (hence N disappears).
From these expressions and from eq. 4, one obtains

and

so that
= 0 only for z* = (F - c)/(F - c2), a formula known since ref. [21]. Together with eq. 7 and the relationship d = (1 - c)z/(1 - cz) between the immigration probability d and the emigration probability z, this yields

Explicitly evaluating d/dz at the candidate ESS would be cumbersome, but it is easily verified that is positive (resp. negative) as z approaches 0 (resp. 1). Since does not vanish between 0 and z*, must increase (resp. decrease) from 0 when z decreases (resp. increases) from z*. Hence, z* is locally convergence stable. Further, at z*,

From this formula,
< 0, i.e. the candidate ESS is indeed an ESS, since cK <F2 at the candidate ESS. The latter result is not obvious, but can be verified as follows. Using eq. 40 to eliminate the three-genes relationship K, the sign of is seen to depend on the sign of the factors F - c (which is positive) and c3 (N2 - 1) + cF - N2F3. The latter is always negative for 0 <c < 1 and N ≥ 1, because the third order polynomial in x, c3 (N2 - 1) + cx - N2x3, has only one real root r, which is such that r < (1 - c + 2cN)/(2N) <F.
The equivalence with the "direct fitness" method previously used to obtain eq. 14 and related results (e.g., [20, 30]) can be verified as follows. According to this method, one considers the fitness function

which describes the expected number of offspring of an individual with dispersal probability z•, in a patch of individuals with mean dispersal z0 in a population with resident dispersal z [20, 30, 31]. Since jw
j
= jw (z + δ, z + j δ/N), and are equal to the two partial derivatives of w, yielding

The term in brackets is the inclusive fitness [20]. One would also obtain (with π1(0) = wp (z*, z*)/N)

where w(i,j)is the derivative of w, i times with respect to z•, and j times with respect to z0. Such expressions are convenient when fitness is exactly a function of z0 (i.e. when the phenotypes of all neighbors do not need to be distinguished), but they may not be useful otherwise.
Competition for resource
Here we consider a model where an individual is in stronger competition with other individuals which have phenotypes similar to its own phenotype. Many previous models are phenomenological, effectively assuming that each individual exploits only one type of resource according to its phenotype, yet that it interferes more with individuals with similar phenotypes. For a population subdivided in small patches, such a model was formulated in ref. [25] and fully analyzed in the case N = 2. However, its formulation is relatively complex, so we will analyze here a slightly different model, and the final section of the Appendix gives comparable results for the model of ref. [25]. Both models have similar qualitative outcomes, which converge for large patch size.
Here we assume that each individual effectively exploits a range of resource and that interference on fitness of similar phenotypes results only from scramble competition for acquisition of resource (e.g., [26]). We consider a range of resource, such that resource of type y has abundance ρ(y), which is the same in all patches. We assume that resource follows a normal distribution,

for some constant σρ, and some ym such that resource ym is the most abundant one. σρ describes the width of the distribution of resource over different types.
We assume that each individual cannot exploit all resources with equal efficiency. An individual i with phenotype z
i
exploits resource y with an efficiency given by an efficiency function α(y, z
i
), such that the individual gets a fraction  of resource y, which is the ratio of its own efficiency at exploiting resource y to the sum of efficiencies at exploiting y among all individuals in the population. We assume that the efficiency function is normal-shaped,
of resource y, which is the ratio of its own efficiency at exploiting resource y to the sum of efficiencies at exploiting y among all individuals in the population. We assume that the efficiency function is normal-shaped,

for some σα, identical for all individuals. Thus, individual i is best at exploiting resource z i , and σα quantifies the diversity of resource that an individual may exploit. An individual strategy is therefore characterized by z i and constrained by the range of resources it can efficiently exploit around z i .
Below we consider residents with strategy z
i
= z and mutants with strategy z
i
= z + δ. Hence, in a patch with j mutants and N - j non-mutants,  .
.
The share s j (δ) of total resource that individual i obtains is its share of resource y, times abundance of resource y, integrated over the distribution of y. Hence, in a patch with j mutants and N - j non-mutants, it is

We assume that the expected number of juveniles of an individual is proportional to this share s j of total resource. The probability that an individual in the offspring generation is the descendant of anyone of j mutant parents in its patch is then
π j (δ) = js j (δ) (1 - d) (22)
and the expected number of successful emigrant gametes of j mutant parents is
h j (δ) = N djs j (δ). (23)
The factor N appears here, as in the dispersal example, because N adults settle in each patch. A general, useful check of expressions for π j and h j is that jw j (0) = j = h j (0) + N π j (0) (from eq. 4).
Here
= - = (ym - z)/ . Hence
. Hence

is of the sign of ym - z, which means, as expected, that the population will evolve to exploit the most abundant resource, z* = ym. In other words, ym is locally convergence stable. At z*, similar computations yield

For given d, F and K become negligible as N increases (they are of the order of 1/N and 1/N2, respectively), and in the limit we recover the result for panmictic populations, that disruptive selection occurs when σα > σρ, i.e. when the resource is more broadly distributed than can be efficiently exploited by one individual.
Population structure inhibits branching, a previously noted result [25] for the interference competition model (see Appendix): for N = 2,

is always negative and, unexpectedly, is independent of σρ (because the term in brackets in eq. 25 is then independent of σρ and proportional to 1/ ). For any N, the exact condition for disruptive selection is 1/ > 1/ + 2(F - K)/(1 - F)/. The latter condition is complex, because
). For any N, the exact condition for disruptive selection is 1/ > 1/ + 2(F - K)/(1 - F)/. The latter condition is complex, because

but it implies that branching is inhibited by small patch size and low dispersal. This result can be understood as follows [25]. There is disruptive selection when a deviant individual gains fitness from avoiding competition with the resident strategy. However, in a subdivided population, competition is preferentially with genetically related individuals, i.e. with individuals more likely to be deviant than the average individual in the population. Then, deviant individuals do not avoid competition as much as if the neighbors in the patch were not related.
Since K is of the order of 1/N2, it may seem reasonable to approximate by setting K = 0. This seems to work well only for N large and d large (Figure 1), because K is not negligible when d → 0 even for large N. Ignoring K will be misleading in this case.

Threshold combinations of values of / and d for disruptive selection. The lines are the thresholds for different values of N. Branching is favored for sets of values in the top right corner delimited by these lines. The dashed line shows the thresholds for N = 12 obtained with the approximation K = 0.
The strategy z* = 0 may be locally stable without being globally stable: < 0 does not exclude that mutants with large effects could invade (for examples, see [32, 33]). Here this may happen for a narrow range of parameter values in the structured population model, even though it does not happen in a single large patch of infinite size. In a single large patch at the candidate ESS, the fitness of a single mutant is

so that large mutations invade if and only if small mutations invade. In structured populations, global stability was investigated by numerical evaluation of Rm, focusing on threshold combinations of / and d such that = 0, that is on the set of parameter values represented by the lines in Figure 1. By continuity, if for some mutants Rm > 1 in the neighborhood of these threshold values, there must be close values of σρ/σα and d such that Rm > 1 for some mutants while < 0, which is the sought phenomenon of global instability despite local stability. It was found to happen for some parameters combinations as shown in Figure 2. Note that Rm can be quite large in some cases, e.g. Rm > 182 for N = 36, d = 1/100 (implying the threshold value /  3.94), and δ = 0.729, so the selective pressures at work could be efficient on a short time scale.
3.94), and δ = 0.729, so the selective pressures at work could be efficient on a short time scale.

Cases of global instability. The shaded area is the set of parameter values for which some mutants invade despite local non-invasibility of the candidate ESS z*. This figure is obtained from computation of Rm for δ up to 2.187.
To some extent, global instability could be sought from higher-order derivatives of Rm. In the present case the symmetry of selection on mutants with effect δ and -δ implies that Rm is an even function of δ around the candidate ESS and that all its odd-order derivatives are null, so at least the fourth-order derivatives should be considered. In practice, this would be very complex.
Discussion
This paper has shown how local evolutionary stability conditions can be computed in structured populations. The expression for
, which determines convergence stability, is consistent with earlier results from inclusive fitness theory. The expression for , which determines evolutionary stability stricto sensu, is new. These are local stability conditions: numerical evaluation of Rm is required to check that mutants of large effect could not invade even if mutants of small effect cannot. Here I will comment on the different roles that relatedness plays in measures of convergence and evolutionary stability, and in this perspective I will discuss the interpretation of the different terms which appear in the computation of and as detailed in the Appendix.
Evaluation of
involves computation of hB'i, and this leads to computation of j2Bi, where j2 = (1,22,...,N2). j2Bi is the sum over generations of the expected square number of descendants of an immigrant in its patch, and therefore in a neutral model it is proportional to relatedness (see eq. 37). Thus we recover expressions for inclusive fitness in terms of relatedness in a neutral model. Here, relatedness describes the probability that two genes have a common ancestor within the patch they are sampled in; this is the property of relatedness that is relevant in relating inclusive fitness to the fitness of rare alleles.
In contrast, evaluation of second-order fitness effect generally requires evaluation of the effect of selection on relatedness. This has been previously acknowledged [10] but not taken into account because it was not found how to compute these effects. This problem has been solved here. Since the term j2Bi is proportional to relatedness, j2B'i is proportional to the derivative of relatedness, and this term is included in . The present analysis further shows that it can be expressed as function of the probability that three genes have a common ancestor within the patch, in a neutral model (see eqs. 51–53).
The different terms of
can be interpreted by distinguishing effects on the distribution of mutant family size in generation t (the parents of the next generation) and effects on the number of offspring of these parents. The first line of the expression for ,

represents second-order effects on the number of offspring of these parents, cumulated over all generations. They include effects on the probability that next-generation individuals will be of philopatric origin (

) and on the production of successful emigrants ( ), which are gathered in the single term
), which are gathered in the single term  . These terms differ from previous expressions for second-order effects: we find a three-gene relationship K [in the terms () K above and w(0,2)K in eq. 18] in place of relatedness in the corresponding term of condition (15b) in [10]. Here K does not appear as measuring an effect of selection on relatedness, but because fitness (w
j
) of a mutant focal individual is affected in a nonadditive way by pairs of mutant neighbors (where individuals are considered "with replacement", so that the focal individual and its two neighbors may all be the same individual).
. These terms differ from previous expressions for second-order effects: we find a three-gene relationship K [in the terms () K above and w(0,2)K in eq. 18] in place of relatedness in the corresponding term of condition (15b) in [10]. Here K does not appear as measuring an effect of selection on relatedness, but because fitness (w
j
) of a mutant focal individual is affected in a nonadditive way by pairs of mutant neighbors (where individuals are considered "with replacement", so that the focal individual and its two neighbors may all be the same individual).
The remainder of
,

is entirely new. It is of order 1/N, so that it cannot be easily neglected relative to other kin competition effects. It compounds first-order effects on the distribution of family size in generation t with first-order effects on the number of offspring of these individuals, h j and π j . The distribution of family size is given by Ati (eq. 2). Therefore, the effects of selection on this distribution are given by derivatives of At, and the cumulative effects of selection over generations are given by derivatives of (I - A)-1 ≡ B. Thus, all expected effects of selection on the genetic structure of the parents in each generation are accounted by B' in the 2(h' + jA')B'i term of eq. 56. The latter term determines the whole expression (30) above. It involves effects not only on relatedness but also on the mean size of the family descended from an immigrant.
Our results have relied upon the highest order term in the expansion of

being j2, and j3 for . In diploid populations with dominance at the locus under selection, the highest order term for would be j3. The evaluation of would involve the three-gene relationship, and would also depend on higher powers of j.
Previous consideration of Rm has been based on the principle that we should compute fitness for a rare mutant [12], where rare means here that fitness effects can be computed by considering a single immigrant mutant in a population of residents. But the concept of convergence stability also requires that when ≠ 0, selection has the same direction whatever the mutant frequency, so that allele invasion implies allele replacement. In the infinite island model, the direction and magnitude of first-order effects on fitness are the same whatever the mutant allele frequency. This is a distinct result owing to a distinct concept of relatedness, the so-called regression definition of relatedness [34, 35]. This relatedness concept serves to describe the probability that two individuals within a patch share the same allele when the allele is not rare in the population, and implies that selection is not frequency-dependent. Thus two distinct concepts of relatedness are called for in the computation of fitness effects on rare mutants and of convergence stability. However, in the infinite island model, the same measure F quantifies both concepts of relatedness, and is appropriate for computing convergence stability. This holds because whether the mutant allele is rare or not, the first-order fitness effects depend on the probability that two gene lineages sampled in a patch have a common ancestor in this patch, i.e. that they descend from the same immigrant [36]. By contrast, evolutionary stability depends on frequency-dependent selection, so no use of the regression definition is called for in the evaluation of the condition for evolutionary stability stricto sensu.
Conclusions
The present paper makes clear the relationship between inclusive fitness concepts and the alternative approach based on the number of successful emigrants. The applications are straightforward. In the dispersal model, branching has never been suggested to occur, and it is shown here that selection is never disruptive at the candidate ESS. This example serves to illustrate the relationship with some techniques from inclusive fitness theory. In the model of competition for resources, population structure inhibits branching. Our results allow a deeper analysis of this example, and we find that there are a few cases of global instability despite local stability.
Appendix
computation of
and
Eigenvectors and eigenvalues of A and B at δ = 0
Computation of the eigenvalues and eigenvectors of A allows evaluation of various expressions involving A and B. However, the expressions for most eigenvectors are complex, and our analyses actually avoid as much of this algebra as possible, except for the few results stated in this section.
Let jm≡ (1,2m...,Nm) be the element-wise product of j with itself m times. Let 1 be the vector (1,...,1) of length N. Let j(m)≡ j(j - 1) ... [j - (m - 1)1], also in terms of the element-wise vector product [i.e., its j th element is j(j - 1)...(j - m + 1)]. Then

where N(m)≡ N(N - 1)...(N - m + 1). This result follows from well-known results for factorial moments of the binomial distribution. The j th element of jkA is the k th moment of the binomial distribution with parameters N and π
j
, hence the j th element of j(m)A is the m th factorial moment of the binomial distribution with parameters N and π
j
, i.e. it is  . For δ = 0, this element is also
. For δ = 0, this element is also  ; from which eq. 31 follows.
; from which eq. 31 follows.
Then, one way to obtain the eigenvalues and eigenvectors of A is to note that  , where the
, where the  's are the Stirling numbers of the second kind [37]. Thus
's are the Stirling numbers of the second kind [37]. Thus  , which relates jkA for any k to lower element-wise powers of j. For k = 1, this yields trivially the first eigenvalue and eigenvector. Together with k = 2, this yields the second eigenvalue and eigenvector, and so on. The eigenvalues of A are
, which relates jkA for any k to lower element-wise powers of j. For k = 1, this yields trivially the first eigenvalue and eigenvector. Together with k = 2, this yields the second eigenvalue and eigenvector, and so on. The eigenvalues of A are

and eigenvectors associated to λ1 and λ2 are e1 = j and e2 = j + [(N - 1)π - 1]j2. It appears that more eigenvectors are not needed.
Conversely

Evaluation of jB, j2B, j2Bi and j3Bi
Note first that 1 - N π1(0) = d. This is a necessary consequence of the fact that the parent of any individual is either from the patch (with probability N π1 when δ = 0), or immigrant (with probability d, by definition, when δ = 0). Then, given B ≡ (I - A)-1,
jB = j(1 - λ1)-1 = j(1 - N π1)-1 = j/d (34)
at δ = 0. Thus, the fitness of a neutral mutant is hBi = d jBi = 1, as it should be.
From eq. 33,

where F is given by eq. 7. Then, j2Bi = NF/d. This result can be obtained by a more enlightening approach.  can be viewed as the expectation of the sum over generations of the squared size j2 of the family descended from an initial mutant. In any generation, expected squared family size is N2 times the probability that two individuals sampled with replacement belong to the same family, i.e. that they descend from the same immigrant. The latter probability is F, as noted in the main text. Then, the sum over a long time T of expected squared family sizes is N2TF. It is also the number of immigrants TNd times the expectation of family size summed over generations since the family's ancestor immigrated into the patch, j2Bi. Hence
can be viewed as the expectation of the sum over generations of the squared size j2 of the family descended from an initial mutant. In any generation, expected squared family size is N2 times the probability that two individuals sampled with replacement belong to the same family, i.e. that they descend from the same immigrant. The latter probability is F, as noted in the main text. Then, the sum over a long time T of expected squared family sizes is N2TF. It is also the number of immigrants TNd times the expectation of family size summed over generations since the family's ancestor immigrated into the patch, j2Bi. Hence
j2Bi = N2TF/(NTd) = NF/d. (37)
This argument is easily generalized to other functions of number of mutants. In particular
j3Bi = N2K/d (38)
where K is the probability that three individuals sampled with replacement in a patch descend from the same immigrant. K can be computed as follows: the three individuals sampled with replacement are either three times the same individual (with probability 1/N2), or two of them are the same and differ from a third [with probability (1 - 1/N)3/N], or they are all distinct. In the latter cases we consider their origin in the previous generation t. These different cases give a recursion over successive generations t and t + 1:

Then, the stationary value of K is

Evaluation of
Consider
= h'Bi + hB'i. (41)
All elements are evaluated at δ = 0. The jth element of h' can be expanded in terms of j and j2 and of model parameters. Let (f) and (f) for the coefficient of j and j2/N in the expression for some quantity f, and expand  in this way. Then
in this way. Then

In δ = 0, h = d j, so that, using B' = BA'B (see [38], p. 151) and eq. 34,
hB' = d jBA'B = jA'B. (43)
The l th element of jA' is the derivative of the expectation of the binomial distribution (1), hence it is  . Then
. Then

and, using eq. 43,

Recall that h j is the expected number of emigrant adults offspring of j mutant adults, and that N π j is the number of adult offspring in the patch of j mutant adults. Hence h j + N π j is simply the expected number of adult offspring of j mutant adults, denoted as jw j (eq. 4). Then from eqs. 42 and 45,

With eqs. 34 and 37, this implies eq. 5.
Evaluation of j2A', j2A'Bi and j2B'i
These computations are preliminary to the computation of
. The j th element of j2A' is the derivative of the second moment of the binomial distribution (1). Hence, it is

Using π j = j π1 at δ = 0, this implies

Then, using eqs. 37 and 38,

Next
j2B'i = j2BA'Bi = NF [(1/d - 1)j + j2] A'Bi (51)
(from eq. 36)

(from eq. 50)

from eq. 43.
Evaluation of 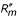
We write

(see [38], p. 152)
=h''Bi + 2(h' + jA')B'i + hBA''Bi (56)
(using eq. 34). Expanding h' and jA' in terms of κ coefficients, and using eqs. 44 and 4, one obtains that the middle term of expression (56) is

(using eq. 53)

using

at the candidate ESS (eq. 5).
The first term of eq. 56 is

and, arguing as in eq. 44, the third term of eq. 56 is

From eq. 4, the
and N terms in the last two expressions can be collected into terms, and then summing expressions 59, 60 and 61 yields eq. 9.
Interference competition
Here, following ref. [25], I assume that the relative number of juveniles produced by each mutant in a patch with j mutants may be written

where the functions ρ and α are defined as in the scramble competition model of the main text (eqs. 19 and 20). This corresponds to eq. 5 in ref. [25], with some change of notation and β there being set to 0. Likewise, the relative number of juveniles produced by each non-mutant in a patch with j mutants is

These numbers are relative to the juvenile production by individuals in other patches, so that the relative total fecundity of a patch [which is j φ
j
(δ) + (N - j) φ
j
(0)] depends on the number of mutants in the patch. By contrast, patch fecundity was constant in the scramble competition model because the total amount of resource was constant in each patch. In the jargon of population genetics, the scramble competition model is a soft selection model while the interference competition model is a hard selection model (e.g., [39]). Assuming that juveniles emigrate with probability  and that there is a relative survival cost c for emigrants (as in the dispersal model),
and that there is a relative survival cost c for emigrants (as in the dispersal model),

and

These expressions are consistent with eqs. 8–10 in ref. [25], in the case of non-overlapping generations. Note that results will be expressed more simply in terms of the probability of immigration

than in terms of the probability of emigration
.
From the above expressions, one obtains as expected that the population converges to z* = ym. In the computation of , it turns out that fitness effects depending on changes in relatedness due to selection are null, because all κ coefficients in the second line of eq. 9 are null (consistent with ref. [25] for N = 2). One obtains

The numerical analysis of this result is similar to that of the scramble competition model, with again some cases of global instability despite local stability being found (details not shown). The main difference is that threshold values of
/ such that = 0 are lower than in the scrambling competition model. That is, disruptive selection occurs more easily. This is seen most easily for strong dispersal, d = 1. In this case F = 1/N and K = 1/N2, so that disruptive selection occurs when (1 - 2/N) > in the scrambling competition model, while it occurs when (1 - 1/N) > in the interference competition model (the latter result being consistent with eq. 18 in [25]). This difference arises because the interference competition model gives a higher benefit to deviant individuals when σρ > σα: in a single large patch at the candidate ESS, the fitness of a rare mutant is
w
j
(δ) = exp [(1/ - 1/) δ2/2 (68)
which is higher than the comparable result for the scramble competition model (eq. 28).
References
Eshel I, Motro U: Kin selection and strong evolutionary stability of mutual help. Theor Popul Biol. 1981, 19: 420-433.
Eshel I: Evolutionary and continuous stability. J Theor Biol. 1983, 103: 99-111.
Christiansen FB: On conditions for evolutionary stability for a continuously varying character. Am Nat. 1991, 138: 37-50. 10.1086/285203.
Abrams PA, Matsuda H, Harada Y: Evolutionarily unstable fitness maxima and stable fitness minima of continuous traits. Evol Ecol. 1993, 7: 465-487.
Eshel I: On the changing concept of evolutionary population stability as a reflection of a changing point of view in the quantitative theory of evolution. J math Biol. 1996, 34: 485-510. 10.1007/s002850050018.
Geritz SAH, Kisdi É, Meszéna G, Metz JAJ: Evolutionarily singular strategies and the adaptive growth and branching of the evolutionary tree. Evol Ecol. 1998, 12: 35-57. 10.1023/A:1006554906681.
Hamilton WD: The genetical evolution of social behavior. I. J Theor Biol. 1964, 7: 1-16.
Doebeli M: The marginal value of relations (book review). J Evol Biol. 1999, 12: 837-838. 10.1046/j.1420-9101.1999.0089e.x.
Frank SA: Foundations of social evolution. Princeton: Princeton University Press. 1998
Day T, Taylor PD: Unifying genetic and game theoretic models of kin selection for continuous traits. J Theor Biol. 1998, 194: 391-407. 10.1006/jtbi.1998.0762.
Rousset F, Billiard S: A theoretical basis for measures of kin selection in subdivided populations: finite populations and localized dispersal. J Evol Biol. 2000, 13: 814-825. 10.1046/j.1420-9101.2000.00219.x.
Metz JAJ, Gyllenberg M: How should we define fitness in structured metapopulation models? Including an application to the calculation of evolutionarily stable dispersal strategies. Proc Roy Soc (Lond) B. 2001, 268: 499-508. 10.1098/rspb.2000.1373.
Parvinen K, Dieckmann U, Gyllenberg M, Metz JAJ: Evolution of dispersal in metapopulations with local density dependence and demographic stochasticity. J Evol Biol. 2003, 16: 143-153. 10.1046/j.1420-9101.2003.00478.x.
Charlesworth B: Evolution in age-structured populations. Cambridge: Cambridge University Press. 1994, 2
Caswell H: Matrix population models. Sunderland, Mass.: Sinauer. 2001
Kisdi É: Evolutionary branching under asymmetric competition. J Theor Biol. 1999, 197: 149-162. 10.1006/jtbi.1998.0864.
Crow JF, Kimura M: An introduction to population genetics theory. 1970, New York: Harper & Row
Rousset F: Genetic structure and selection in subdivided populations. 2004, Princeton, New Jersey: Princeton University Press
Taylor PD: An inclusive fitness model for dispersal of offspring. J Theor Biol. 1988, 130: 363-378.
Taylor PD, Frank SA: How to make a kin selection model. J Theor Biol. 1996, 180: 27-37. 10.1006/jtbi.1996.0075.
Frank SA: Dispersal polymorphism in subdivided populations. J Theor Biol. 1986, 122: 303-309.
Holt RD, McPeek MA: Chaotic population dynamics favors the evolution of dispersal. Am Nat. 1996, 148: 709-718. 10.1086/285949.
Doebeli M, Ruxton GD: Evolution of dispersal rates in metapopulation models: branching and cyclic dynamics in phenotype space. Evolution. 1997, 51: 1730-1741.
Mathias A, Kisdi É, Olivieri I: Divergent evolution of dispersal in a heterogeneous landscape. Evolution. 1999, 55: 246-259.
Day T: Population structure inhibits evolutionary diversification under competition for resources. Genetica. 2001, 112–113: 71-86. 10.1023/A:1013306914977.
Christiansen FB, Loeschke V: Evolution and intraspecific exploitative competition I. One-locus theory for small additive gene effects. Theor Popul Biol. 1980, 18: 297-313.
Roughgarden J: The theory of coevolution. In Coevolution. Sunderland, Mass: Sinauer. Edited by: Futuyma DJ, Slatkin M. 1983, 33-64.
Taper ML, Case TJ: Models of character displacement and the theoretical robustness of taxon cycles. Evolution. 1992, 46: 317-333.
Doebeli M, Dieckmann U: Evolutionary branching and sympatric speciation caused by different types of ecological interactions. Am Nat. 2000, 156: S77-S101. 10.1086/303417.
Gandon S, Rousset F: Evolution of stepping stone dispersal rates. Proc Roy Soc (Lond) B. 1999, 266: 2507-2513. 10.1098/rspb.1999.0953.
Lehmann L, Perrin N: Altruism, dispersal, and phenotype-matching kin recognition. Am Nat. 2002, 159: 451-468. 10.1086/339458.
Jansen VAA, Mulder GSEE: Evolving biodiversity. Ecol Lett. 1999, 2: 379-386. 10.1046/j.1461-0248.1999.00100.x.
Gandon S, Mackinnon M, Nee S, Read A: Imperfect vaccination: some epidemiological and evolutionary consequences. Proc Roy Soc (Lond) B. 2003, 270: 1129-1136. 10.1098/rspb.2003.2370.
Hamilton WD: Selfish and spiteful behaviour in an evolutionary model. Nature. 1970, 228: 1218-1220.
Grafen A: A geometric view of relatedness. Oxford Surv Evol Biol. 1985, 2: 28-89.
Rousset F: Inbreeding and relatedness coefficients: what do they measure?. Heredity. 2002, 88: 371-380. 10.1038/sj.hdy.6800065.
Abramovitz M, Stegun IA, Eds: Evolution in age-structured populations, Handbook of mathematical functions. New York: Dover. 1972
Magnus JR, Neudecker H: Matrix differential calculus with applications in statistics and econometrics. Chichester, UK: Wiley. 1999, Revised
Christiansen FB: Hard and soft selection in a subdivided population. Am Nat. 1975, 109: 11-16. 10.1086/282970.
Acknowledgements
I thank Troy Day and two anonymous reviewers for useful comments. F. Rousset held the pen.
Author information
Authors and Affiliations
Corresponding author
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
About this article
Cite this article
Ajar, É. Analysis of disruptive selection in subdivided populations. BMC Evol Biol 3, 22 (2003). https://doi.org/10.1186/1471-2148-3-22
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1471-2148-3-22